随着信息技术的迅猛发展,人们获取新闻资讯的方式从传统媒体转向了数字化平台。信息过载问题日益凸显,用户难以从海量新闻中快速找到自己感兴趣的内容。个性化推荐系统应运而生,成为解决这一问题的关键技术。本文旨在探讨一个基于SpringBoot框架,采用协同过滤算法实现的新闻推荐系统(项目参考编号:9k0339),该系统旨在为计算机系统服务领域提供一个高效、可扩展的个性化新闻推荐解决方案。
1. 系统概述与背景
本系统被归类为“计算机系统服务”,核心目标是构建一个智能化的新闻分发平台。通过分析用户的历史浏览记录、点击行为及评分数据,系统能够自动学习用户的兴趣偏好,并为其推荐可能感兴趣的新闻文章,从而提升用户体验和信息获取效率。SpringBoot框架因其简化配置、快速开发、微服务友好等特性,被选为系统后端开发的基础,确保了系统的高效构建与稳定运行。
2. 核心技术:协同过滤算法
协同过滤是本推荐系统的核心算法。它主要分为两类:
- 基于用户的协同过滤:通过寻找与目标用户兴趣相似的其他用户,将这些相似用户喜欢而目标用户未浏览过的新闻推荐给目标用户。其关键在于计算用户之间的相似度(如余弦相似度或皮尔逊相关系数)。
- 基于物品的协同过滤:通过分析新闻文章之间的相似性(例如,被同一批用户点击或喜欢),将与用户历史喜好新闻相似的其他新闻推荐给用户。这种方法通常更稳定,因为新闻间的相似性比用户兴趣的变化更缓慢。
本系统计划结合两种方法的优势,并采用矩阵分解等优化技术来处理数据稀疏性和冷启动问题,提高推荐的准确性和覆盖率。
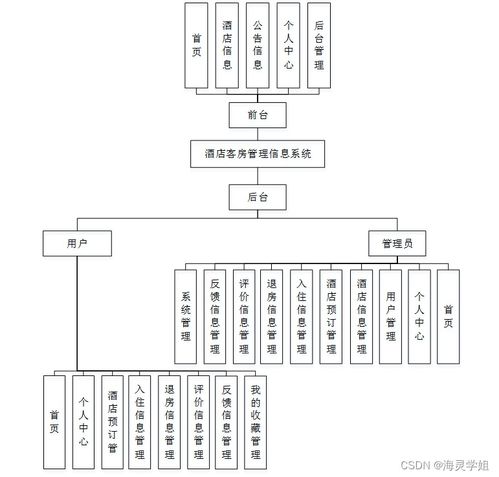
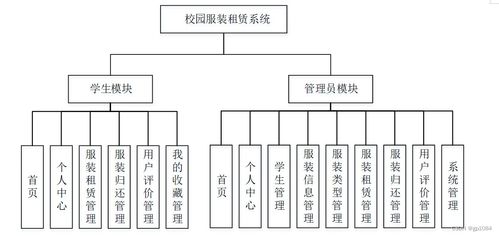
3. 系统架构设计与模块划分
系统采用经典的分层架构,主要分为以下模块:
- 数据采集与处理层:负责收集用户行为日志(点击、停留时长、评分)、新闻元数据(标题、分类、标签、发布时间)。使用Flume、Kafka等工具进行日志采集,并利用Hadoop或Spark进行离线数据清洗与特征提取,为推荐算法准备高质量的数据集。
- 推荐引擎核心层:这是系统的“大脑”。它接收处理后的数据,运行协同过滤算法模型,定期(如每日)更新用户兴趣模型和新闻相似度矩阵,并实时响应用户的推荐请求。算法模块可以设计为可插拔的,便于未来集成更复杂的深度学习模型。
- 业务应用层(SpringBoot后端):基于SpringBoot构建RESTful API,提供用户注册登录、新闻浏览、行为上报、个性化推荐列表获取、反馈收集(如喜欢/不喜欢)等功能。该层负责衔接前端与推荐引擎,处理业务逻辑。
- 数据存储层:采用混合存储策略。用户信息、新闻元数据等结构化数据存储在MySQL中;用户行为日志、大规模的相似度矩阵等则存储在Redis(缓存热数据)和HBase或MongoDB(存储历史与稀疏矩阵)中,以平衡性能与容量。
- 前端展示层:通常使用Vue.js或React等框架开发响应式Web界面,直观展示新闻列表、推荐栏目及用户个人中心。
4. 关键实现流程
- 用户行为建模:系统持续记录用户的隐性反馈(如点击、阅读完成度)和显性反馈(如评分、点赞)。这些数据是协同过滤算法训练的燃料。
- 相似度计算与模型训练:离线任务周期性地计算用户-用户相似度或新闻-新闻相似度,并生成推荐模型。SpringBoot可以集成调度框架(如Quartz)来管理这些定时任务。
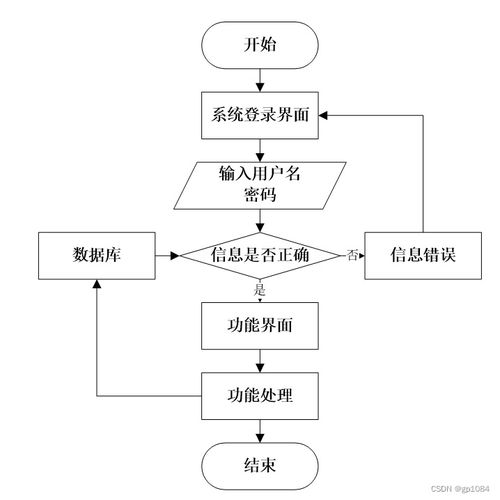
- 实时推荐:当用户访问系统时,后端API根据其ID,从推荐模型中检索出Top-N的新闻ID列表,再结合新闻热度、时效性等因素进行加权排序,最终生成个性化的推荐列表返回给前端。
- 效果评估与优化:通过A/B测试,对比不同算法或参数下的点击率、转化率等指标,持续优化推荐效果。系统需预留评估接口。
5. 项目特色与挑战应对
- 特色:系统充分结合了SpringBoot的工程化优势和协同过滤算法的成熟性,实现了一个从数据到服务的完整闭环。模块化设计使得算法部分易于迭代升级。
- 挑战与应对:
- 冷启动问题:对于新用户或新新闻,采用基于内容的推荐(分析新闻关键词、分类)或热门新闻推荐作为补充,待数据积累后再启用协同过滤。
- 系统性能:利用Redis缓存热门推荐结果和用户会话信息,确保高并发下的响应速度。SpringBoot的内置Tomcat容器和微服务理念便于水平扩展。
- 可扩展性:通过将推荐引擎设计为独立服务,可以方便地将其部署为Docker容器,并集成到更大的微服务生态中。
6. 与展望
本项目设计的基于SpringBoot和协同过滤的新闻推荐系统,为计算机系统服务提供了一个实践性强的毕业设计范例。它不仅涵盖了现代Web系统开发的主流技术栈,还深入应用了经典的数据挖掘算法。该系统可以进一步探索基于深度学习的混合推荐模型,引入实时流处理技术(如Flink)进行在线学习,并加强推荐结果的多样性和可解释性,从而向更智能、更人性化的推荐服务平台演进。